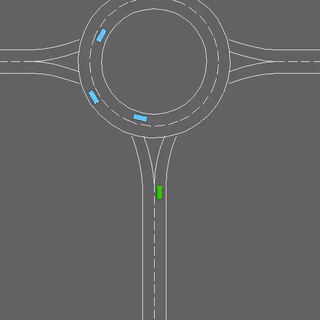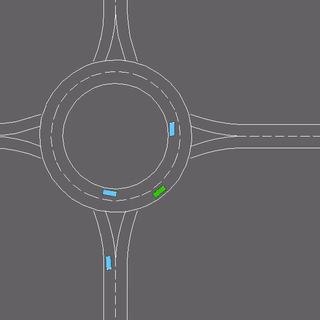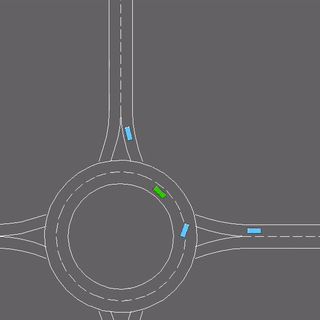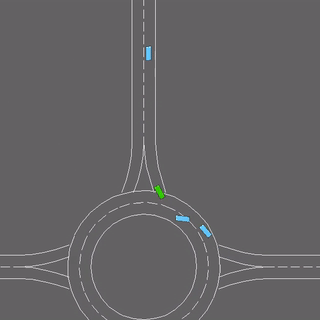
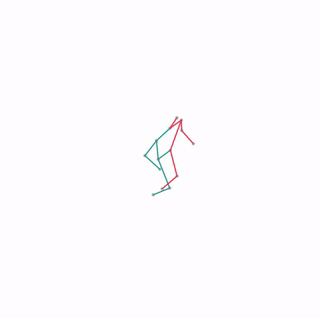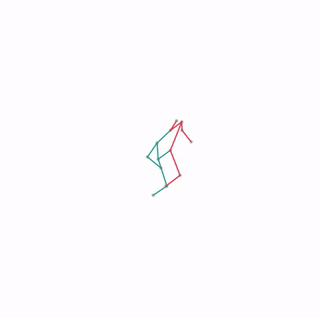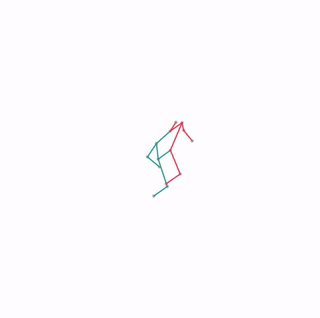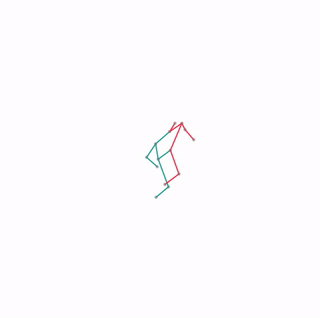Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples.
We refer to this problem as task concept learning, and present our approach, Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM), which learns new task concepts by leveraging invertible neural generative models.
The core idea is to pretrain a generative model on a set of basic concepts and their demonstrations.
Then, given a few demonstrations of a new concept (such as a new goal or a new action), our method learns the underlying concepts through backpropagation without updating the model weights, thanks to the invertibility of the generative model.
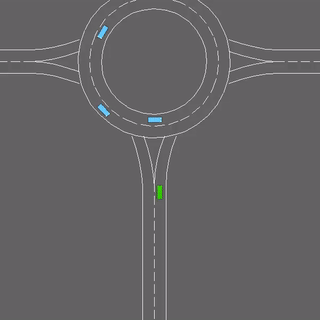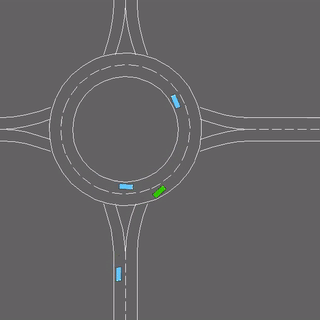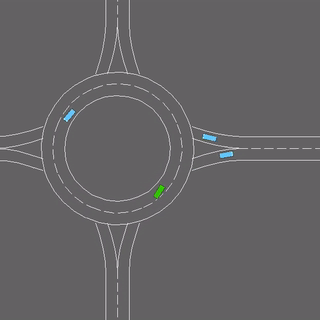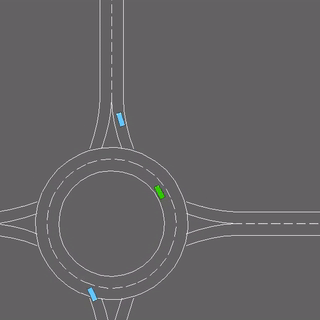
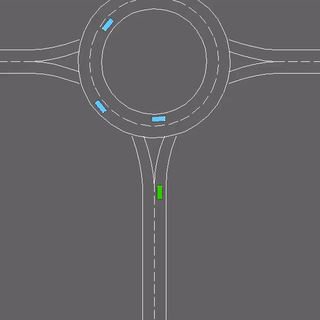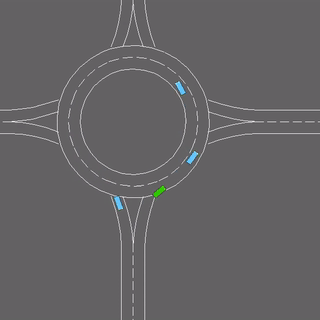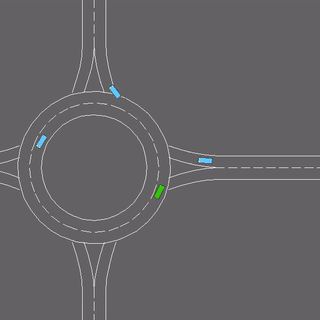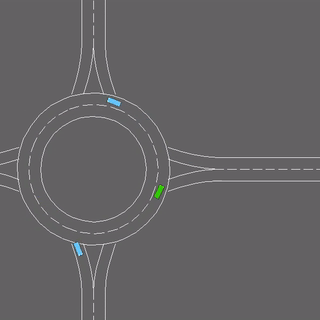
We evaluate our method in five domains -- object rearrangement, goal-oriented navigation, motion caption of human actions, autonomous driving and real-world table-top manipulation.
Our experimental results demonstrate that via the pretrained generative model, we successfully learn novel concepts and generate agent plans or motion corresponding to these concepts in (1) unseen environments and (2) in composition with training concepts.